
TensorFlow で 画像分類モデルを構築してみた・後編
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは!よしななです。
前回の記事で、TensorFlow による私の飼い猫とそれ以外の猫の判別モデルを構築し、テストデータを用いてモデルの評価をするところまでを行いました。今回は、前回構築したモデルの精度改善の手法をいくつか調べたので、備忘録としてブログに残します。
前回のブログ:
目次
- 開発環境・実行環境について
- 目的
- 前回構築したモデルについて
- モデルの学習経過
- モデルの精度
- モデルの精度改善をやってみる
-
- データ数を増やしてみる
-
- データ拡張を実行
-
- 画像ごとの輝度の平均を求める
-
- 学習率スケジュールの調整
-
- モデルの学習経過
- モデルの精度評価
- データの用意
- テストデータでのモデルの予測・評価
- 終わりに
開発環境・実行環境について
前回の記事では、google colab を使用し、データ前処理~テストデータを用いてモデル評価までを実行しました。今回も前回と同様の環境で行います。
- 実行環境
- Google Colaboratory 上でモデルの構築を実行
- python : 3.9
- 各ライブラリは Google Colab 上でインポートする
- Google Colaboratory 上でモデルの構築を実行
また、本記事のコードを実行したい場合、前回の記事で構築したモデルが必要になります。
目的
TensorFlow による私の飼い猫とそれ以外の猫の判別モデルの精度改善アプローチを調査し、
実行して精度が改善されるかを確かめます。
前回構築した CNN モデルについて
前回のモデル構築結果は以下の通りです。
結果を元に、改善アプローチを考えてみます。
CNN モデルの学習経過
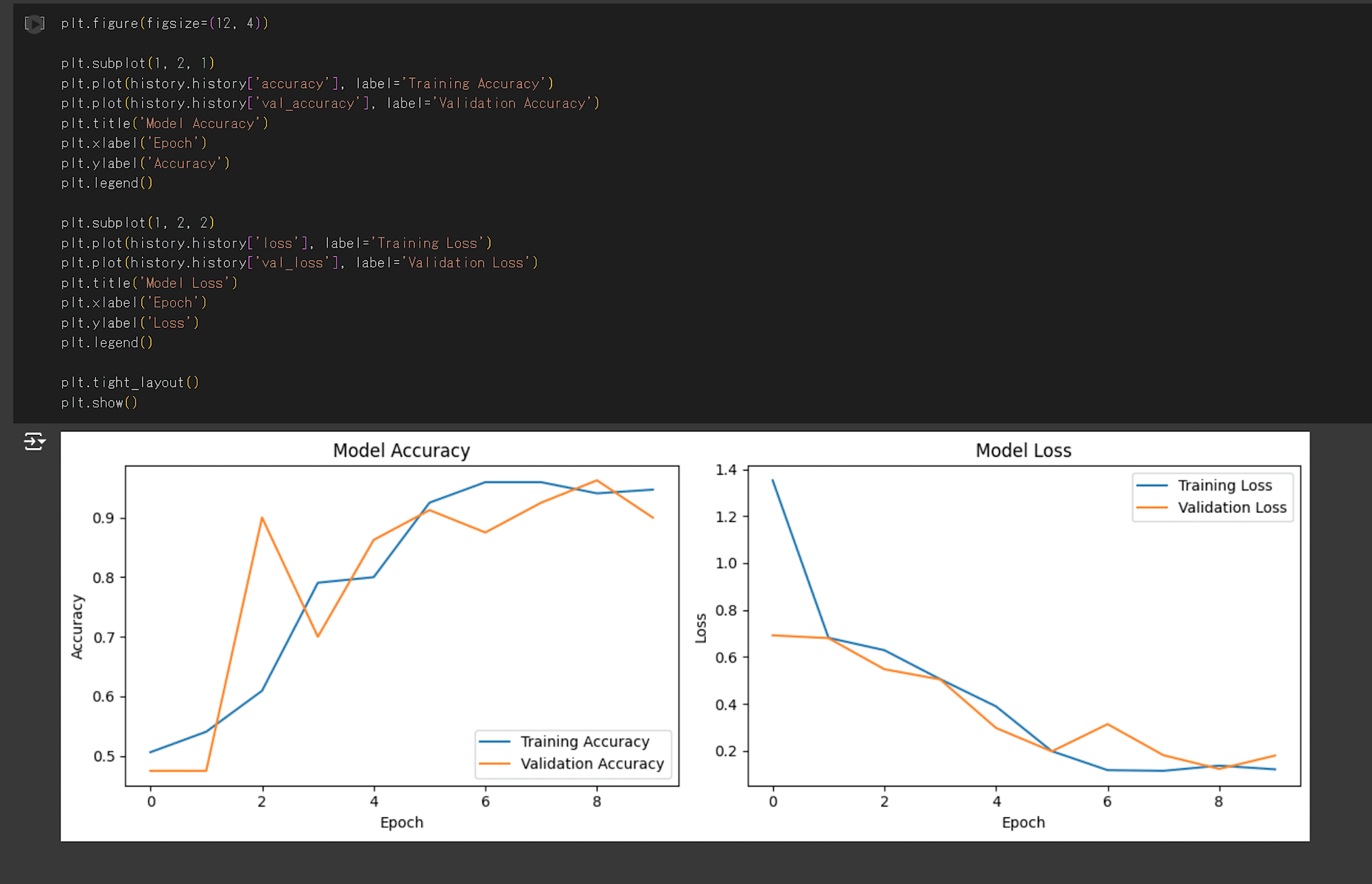
それぞれ、エポック数(モデルにデータを学習させた回数)ごとの損失関数と正解率を出力しています。
グラフを確認すると、6エポック目で正解率はほとんど変化が見られなくなり、検証データの損失関数が増加しています。
そのため、今回の CNN モデルは6エポックで学習を停止するのがよさそうです。
モデルの精度
正解率、適合率、再現率、F1スコア
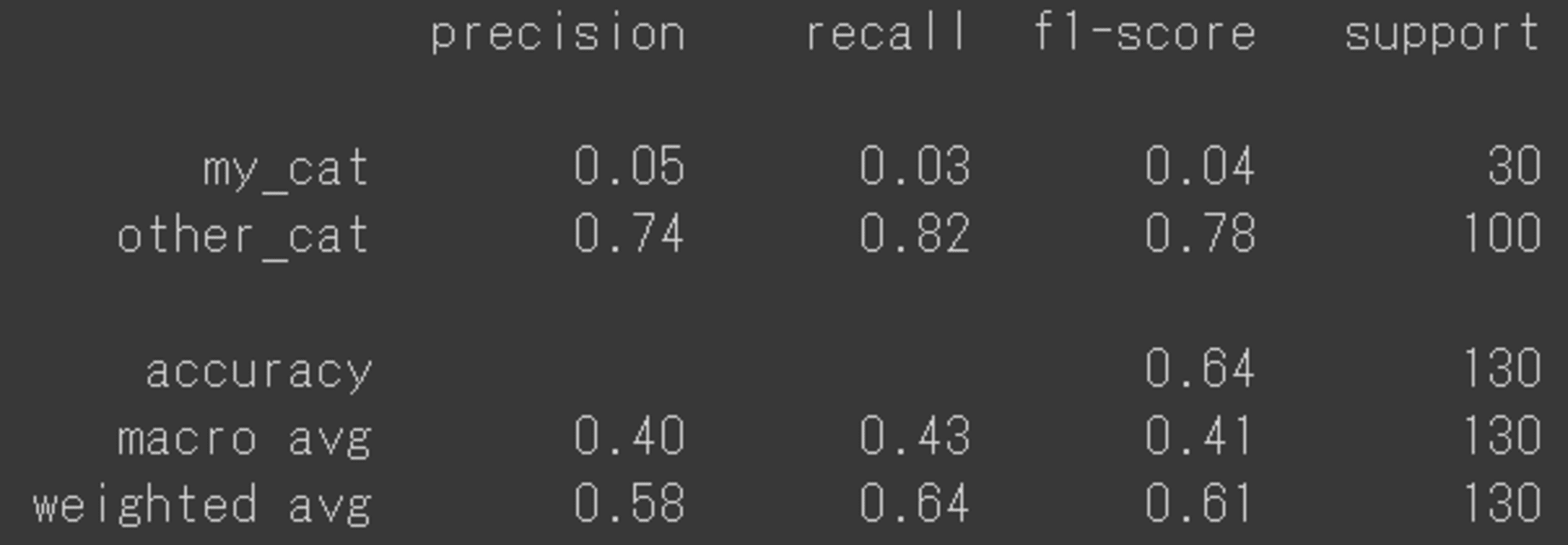
Precision(適合率)、Recall(再現率)を見てみると、my_catとother_catの値に大幅な乖離があることが分かります。
この結果から、other_catクラスの分類性能は比較的良好ですが、my_catクラスの分類性能が非常に低いことがわかります。
全体的な正解率は64%ですが、クラス間で大きな不均衡があるため、my_catクラスの分類改善が必要そうだということが分かりました。全体的に画像データが少ないのと、用意した飼い猫の画像は横を向いている画像が多かったため、そのあたりも精度に関係していそうです。
ROC 曲線・混同行列
前回構築した ROC 曲線と混同行列のグラフは以下となります。
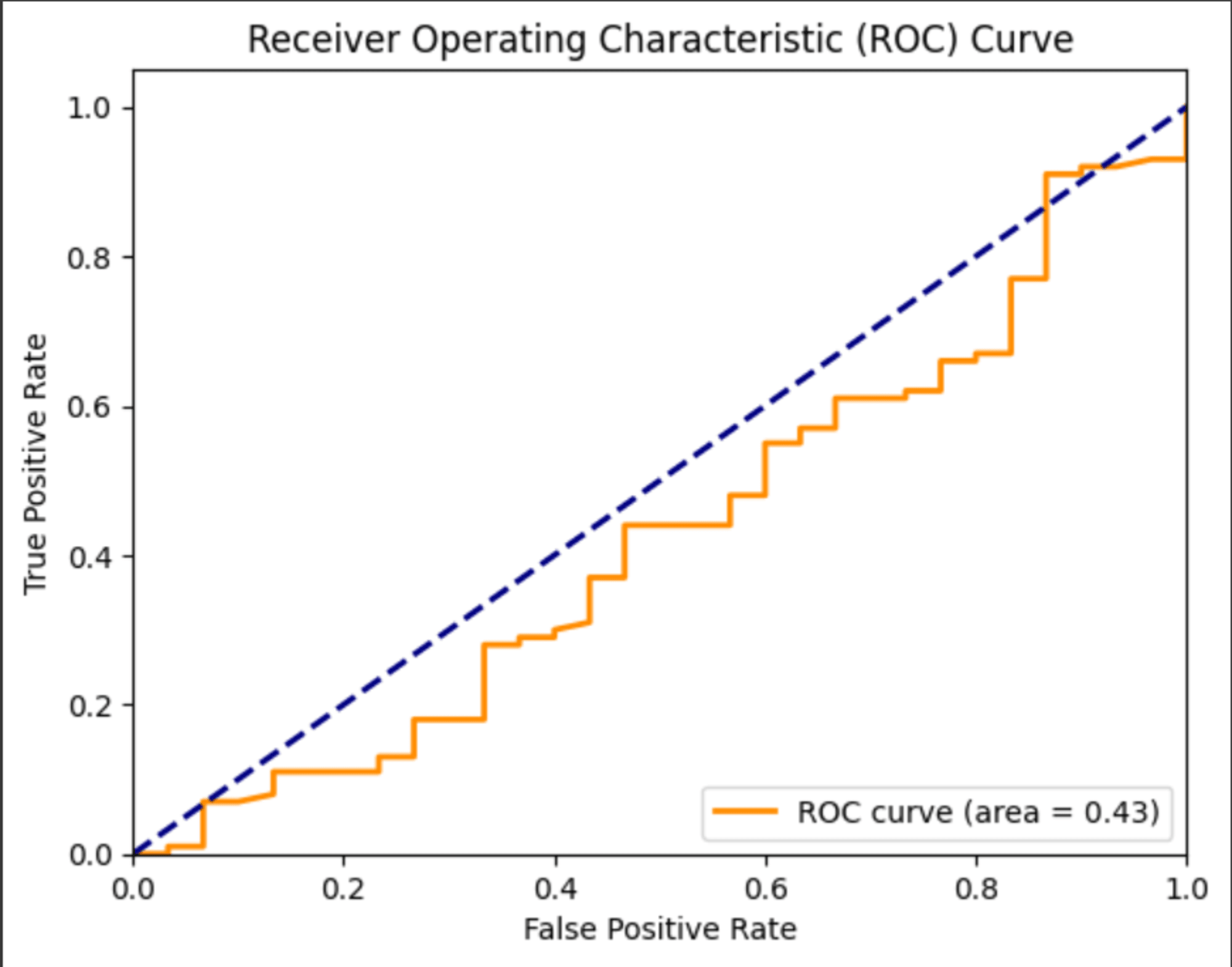
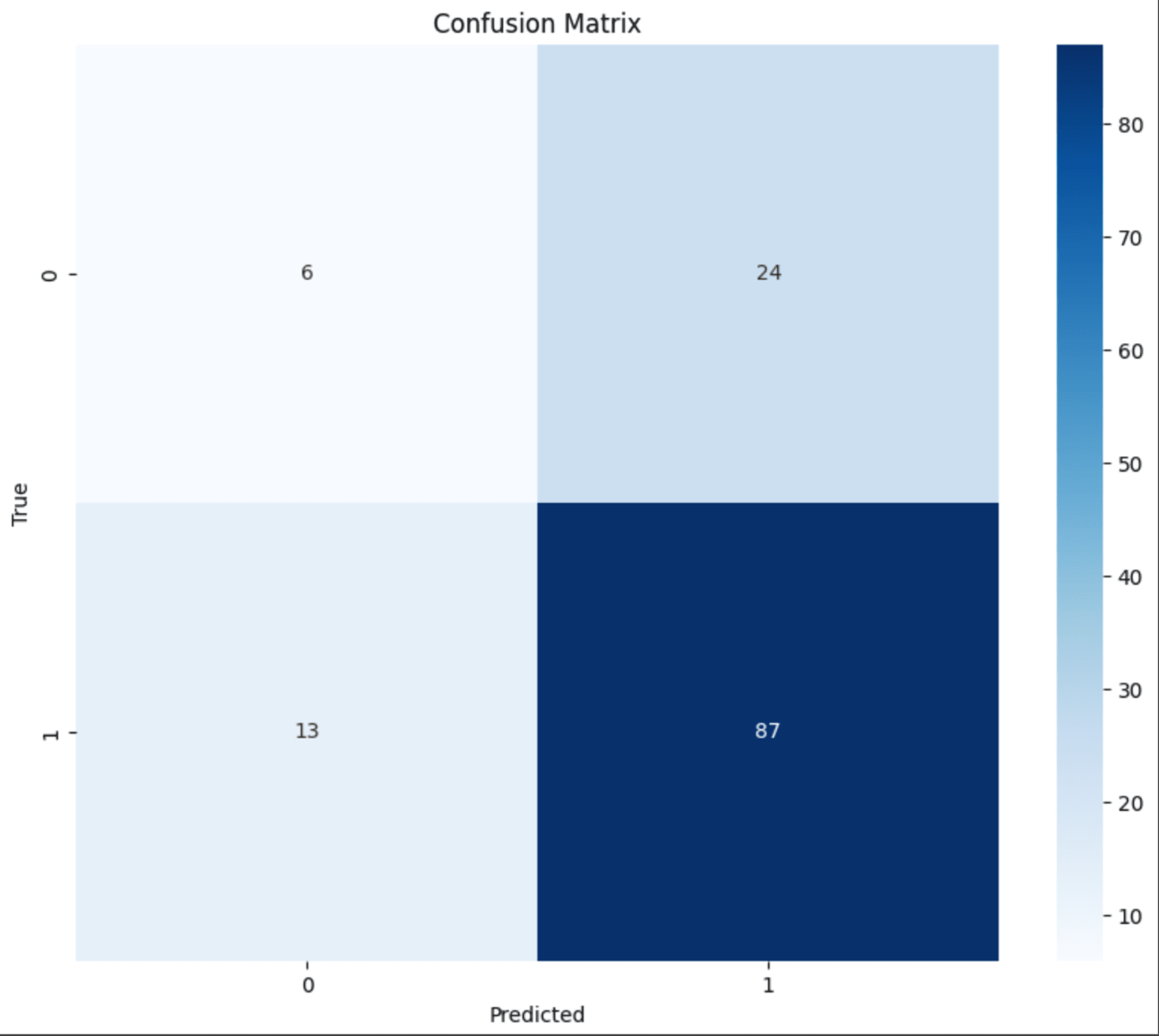
モデルの精度改善を試してみる
上記の結果から、モデルの精度改善アプローチを考えてみました。
以下についてそれぞれ実行した内容をまとめます。
- データ数を増やしてみる
- データ拡張を実行
- 画像ごとの輝度の平均を求める
- 学習率スケジュールの調整
1. データ数を増やしてみる
前回、モデル構築に使用したデータについて、学習用・検証用データが合わせて400枚と少ない状態でモデルを構築していたため、学習用・検証用データを900枚に増やし、学習用データ:630枚、検証用データ:270枚にそれぞれ分割しました。
また、前回用意したデータでは飼い猫の正面画像が少なかったため、なるべく正面画像を用意しました。

以下の通り画像フォルダを作成します。
- 正解データ : 自分で撮影した飼い猫の写真450枚
- 正面画像を用意
- 不正解データ : Kaggle データセットの猫画像450枚をランダムに取得
- kaggleリンク : https://www.kaggle.com/c/dogs-vs-cats
2. データ拡張を実行
次に、データ拡張を行いデータ数を増やしてモデルを学習します。
データ拡張はSequentialモデルの入力層に組み込みます。
tf.keras.layers.RandomFlipと、tf.keras.layers.RandomZoomを使用します。
公式ドキュメント:
データ拡張の注意点
データ拡張は、像に対して様々な変換を施すことで、データを水増しします。
しかし、データ拡張を行う際は注意点があります。以下の画像image1~image3を見てみます。

image1 の猫の画像に対しデータ拡張を行い、image2、image3 を作成しました
image2 は画像に対してズーム処理を行い、image3 は上下反転処理を行っています。
まず image2 に関してですが、猫を写真撮影する際、ズームのレベル感は撮影者に委ねられている場合が多いです。
そのため、全体像が写るように引いた写真を撮る人もいれば、猫の顔だけ拡大する写真を撮る人もいるかもしれません。
なので、image2 のデータ拡張は有効そうであると考えられます。
反対に、image3 は画像が 180° 回転されていて猫が逆さまになっています。
座っている猫を逆さまに撮る人はいないと考えられますし、座っている猫が逆さまになる状態を目撃することは考えられないため、image3 のデータ拡張は有効ではないと考えられます。
猫の撮影状況を考えて、今回は画像を以下の通り加工し、データ拡張を行います。
- 正規化(画像のピクセルを 1~255 → 0~1 でスケーリングする)
- ランダムに水平反転
- ランダムにズーム
以下のコードを実行します。
# data_augmentation に格納
data_augmentation = tf.keras.Sequential([
tf.keras.layers.RandomFlip(mode="horizontal"),
tf.keras.layers.RandomZoom(0.1)
])
# モデル構築
# 画像入力
image_input = tf.keras.Input(shape=(img_height, img_width, 3))
x = data_augmentation(image_input)
x = tf.keras.layers.Conv2D(32, 3, activation='relu')(x)
x = tf.keras.layers.MaxPooling2D()(x)
x = tf.keras.layers.Conv2D(64, 3, activation='relu')(x)
x = tf.keras.layers.MaxPooling2D()(x)
x = tf.keras.layers.Conv2D(128, 3, activation='relu')(x)
x = tf.keras.layers.MaxPooling2D()(x)
x = tf.keras.layers.Flatten()(x)
x = tf.keras.layers.Dense(128, activation='relu')(x)
import matplotlib.pyplot as plt
import numpy as np
# 画像とラベルを取得
images, labels = next(image_input)
# 3x3のグリッドを作成
fig, axes = plt.subplots(3, 3, figsize=(9, 9))
fig.suptitle("Augmented Images with Labels", fontsize=9)
for i, (image, label) in enumerate(zip(images, labels)):
if i >= 9: # 9枚の画像のみ表示
break
row = i // 3
col = i % 3
# 画像を表示
axes[row, col].imshow(image)
# ラベルを設定
label_text = "my_cat" if label == 0 else "other_cat" # バイナリ分類を仮定
axes[row, col].set_title(f"{label_text}")
# 軸を非表示に
axes[row, col].axis('off')
plt.tight_layout()
plt.show()
実行した結果は以下となります。
画像が加工されていることを確認しました。

3. 画像ごとの輝度の平均を求める
飼い猫は白い猫なので、画像の平均輝度を計算し、一定のしきい値を超えた場合に「白い猫」と判断するような特徴量を以下のコードで追加してみます。
やり方としては、以下の通りです。
- 画像をグレースケール変換
- 入力されたグレースケール画像
grayから、画像全体の平均輝度値を算出 - 閾値
thresholdを越えたら白(0)、超えないなら黒(1)を画像に渡す
以下のコードを実行します。
# カスタム層の定義
class BrightnessLayer(tf.keras.layers.Layer):
def __init__(self, threshold=200, **kwargs):
super(BrightnessLayer, self).__init__(**kwargs)
self.threshold = threshold
def call(self, inputs):
# グレースケールに変換
gray = tf.image.rgb_to_grayscale(inputs)
# 平均輝度を計算
avg_brightness = tf.reduce_mean(gray, axis=[1, 2])
# しきい値との比較(0 or 1)
is_white = tf.cast(avg_brightness > self.threshold, tf.float32)
return is_white
# データ読み込みと前処理の関数
def load_and_preprocess(image, label):
# 正規化の実施
image = tf.cast(image, tf.float32) / 255.0
# 輝度を計算する
brightness = BrightnessLayer()(image)
return (image, brightness), label
# データセットに前処理を適用
train_ds = train_ds.map(load_and_preprocess,load_and_preprocess)
val_ds = val_ds.map(load_and_preprocess,load_and_preprocess)
4. 学習率スケジュールの追加
次に、前回のモデルと比較し、学習率スケジュールを追加していきます。
CNN における学習率(learning rate)とは、ニューラルネットワークが学習中にパラメータを更新する際のステップの大きさを決める重要なハイパーパラメータです。
学習率が大きすぎると学習が発散してしまい、モデルがうまく収束しない可能性があります。
逆に、学習率が小さすぎると収束するまでに非常に長い時間がかかったり、ローカルミニマム(局所最小値)に陥ってしまう可能性があります。
CNNでは、学習率の調整が特に重要になることが多いです。
画像データを扱う際には、データの複雑さや量が多く、適切な学習率を見つけ出すことが、モデルの性能を最大化する鍵になります。
今回は、以下の通り設定します。
initial_learning_rateで初期学習率を設定 : 今回は 1e-3(0.001)decay_steps: 100ステップごとに学習率が減衰しますdecay_rate: 各減衰ステップで学習率が90%になりますstaircase: 階段状の減衰を行います(Falseの場合は連続的な減衰)
以下のコードを実行します。
# 学習率スケジュールの設定
initial_learning_rate = 0.001
lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate,
decay_steps=100,
decay_rate=0.9,
staircase=True)
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=lr_schedule),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['accuracy'])
)
# モデルの学習
# モデルの訓練
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=6,
verbose=1
)
精度(Accuracy)と損失(Loss)の推移
モデルのトレーニングが完了したので、トレーニングした CNN モデルの学習過程を可視化していきます。
ここでは、「モデルがどのようにトレーニングされているのか」、「モデルの学習中に問題が起こっていないか」を見ていきます。
損失関数(loss)、正解率(accuracy)がモデルのトレーニング中にどのように推移していったのかを可視化します。
以下のコードを実行します。
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(history.history['accuracy'], label='Training Accuracy')
plt.plot(history.history['val_accuracy'], label='Validation Accuracy')
plt.title('Model Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.title('Model Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.tight_layout()
plt.show()
結果は以下の通りです。
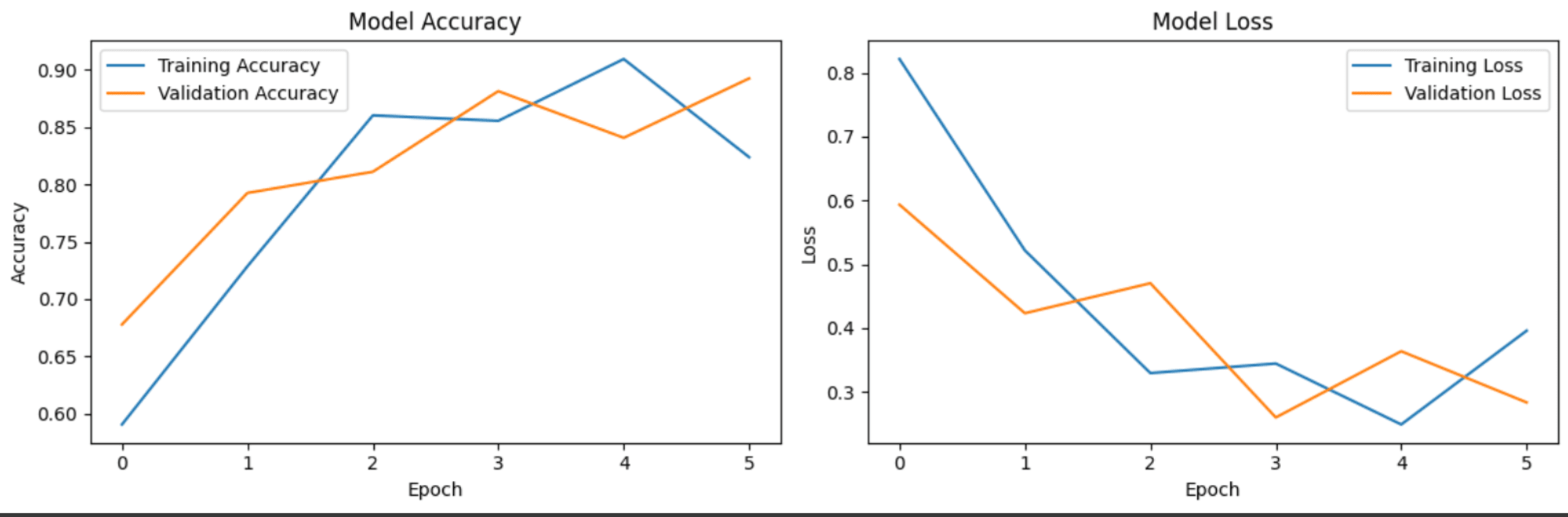
上記の実験結果を見ると、学習データ、検証データともに大幅なずれがなく、正解率もエポックを重ねるごとに上昇しています。また、損失関数の大幅な増減がないため過学習は発生していないと考えられそうです。
テストデータでの評価
最後に、テストデータを用いて構築したモデルの精度評価を行います。
データの用意
トレーニングデータと同様に、Google Drive にアップロードしたデータを解凍します。
import zipfile
local_zip = "/content/test_cat_data.zip"
zip_ref = zipfile.ZipFile(local_zip, "r")
zip_ref.extractall()
zip_ref.close()
テストデータのリサイズを行います。
test_ds = tf.keras.utils.image_dataset_from_directory(
"/content/test_cat_data",
image_size=(180, 180),
batch_size=32
)
テストデータでのモデルの予測・評価
次に、テストデータを用いて精度改善アプローチを実施したモデルに対し、予測と精度評価を実施します。
分類モデルの性能評価
sklearnのclassification_reportモジュールを使用して、
my_catラベルとother_catそれぞれの正解率、適合率、再現率、F1スコアを出力します。
以下のコードを実行します。
from sklearn.metrics import classification_report
# テストデータセットで予測を行う
y_pred = model.predict(test_ds)
y_pred_classes = np.argmax(y_pred, axis=1)
y_true = np.concatenate([y for x, y in test_ds], axis=0)
# 分類レポートを表示
print(classification_report(y_true, y_pred_classes, target_names=['my_cat', 'other_cat']))
以下の結果が出力されました。
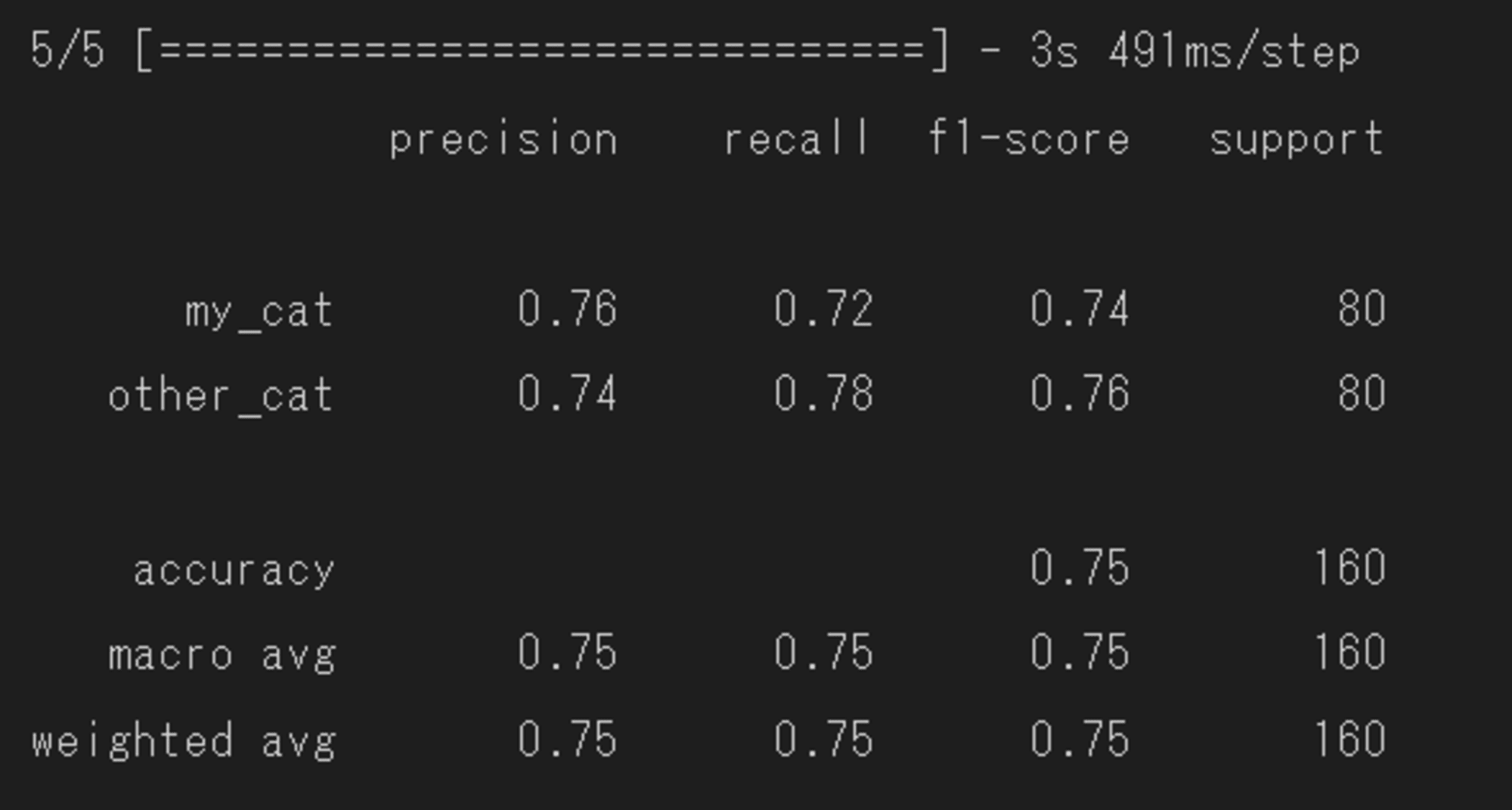
結果を確認すると、正解率は80%を越えず75%に落ち着きましたが、前回と比較し全体的にモデルの精度に改善が見られました。
特に、my_catの分類能力が向上したため、全体の正解率に改善が見られました。
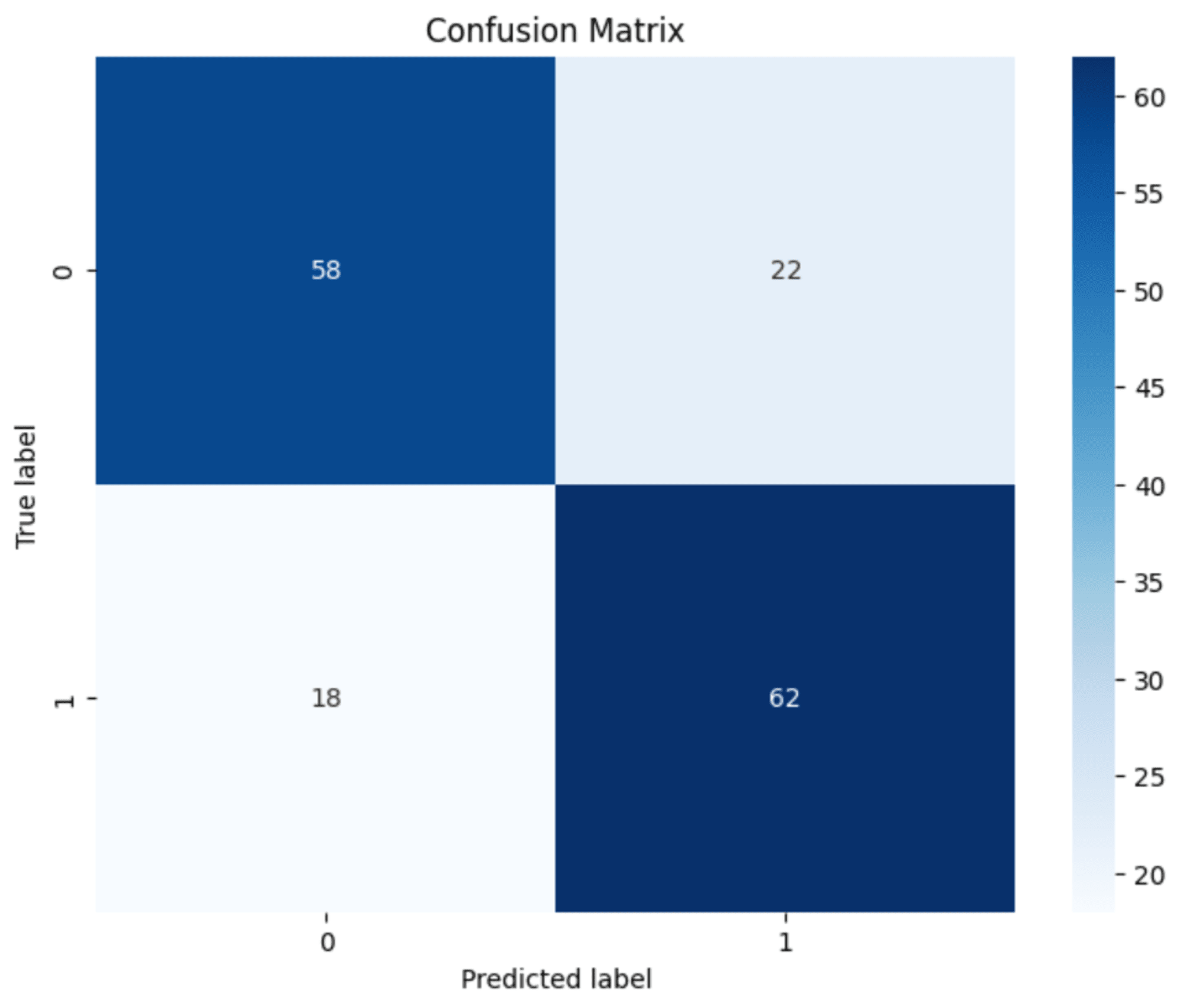
また、混同行列も確認したところ、それぞれTP(真陽性)、TN(真陰性)が全体のデータセットの7割ほど分類されていることを確認しました。
まだまだ改善の余地はありますが、前回と比較し精度が上がったのでよかったです。
他に精度を上げるアプローチが思いついたら記事にしたいと思います。
終わりに
以上で、「TensorFlow で 画像分類モデルを構築してみた・後編」は以上となります。
精度改善といっても、新しく特徴量を加えたり、モデル側でパラメータを調整したり、そもそもデータを新しく足してみたり…と様々なアプローチがあるということが学べました。
ここまで読んでいただきありがとうございました。






